Azure Synapse Analytics –Part 2: Creating a Workspace

This is the second series of articles on Azure Synapse Analytics. Check out our first article from the series that explains the basics of Azure Synapse Analytics. This article will explain the detailed steps to create an Azure Synapse Analytics Workspace in the Microsoft Azure portal.
Important Prerequisites
- You must have a Microsoft Azure account with a valid subscription
- You must have access to the resource group for which you are assigned the “Owner” role. The Synapse Workspace will be a part of this resource group.
Step 1: Creating the Azure Synapse Analytics Workspace Resource
In the Azure portal, click “Create a resource” under Azure services in the Home page. Search for “Azure Synapse Analytics”. Click the search result to open the Azure Synapse Analytics page. On this page, click Create to create a new workspace resource.
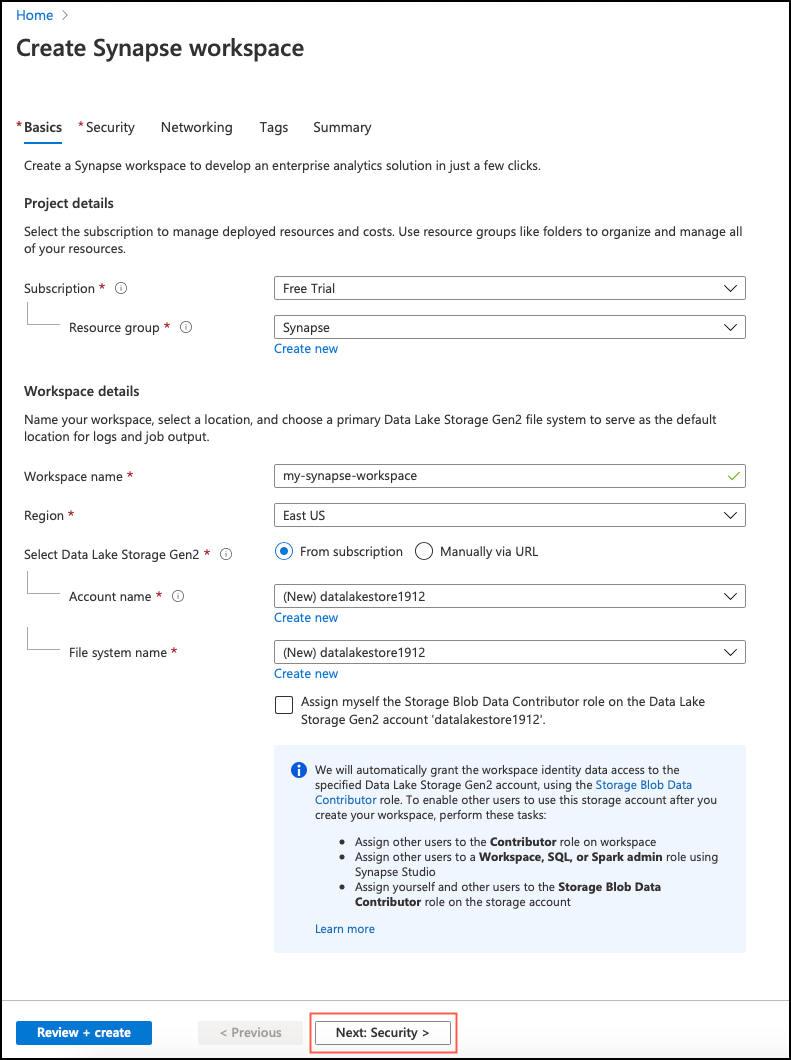
In the Basics tab, enter the project details (select the subscription and resource group), workspace details (provide a name, select the region, select the Data Lake Storage Gen2 from the list). The workspace name should only contain lowercase characters or numbers or hyphens.
If you do not have a Resource Group and/or Data Lake Storage Gen2 resource already created, click Create New to create a new resource group and Data Lake Storage Gen2 resource. We will create the Data Lake Storage account and name it as “datalakestore1912”. This storage account will store the data such as blobs, files, tables, queues. For the Data Lake Storage file system name, we will create it with the same name as the account (datalakestore1912). Select the checkbox if you want to have the “Storage Blob Data Contributor” role on this Data Lake Storage account.
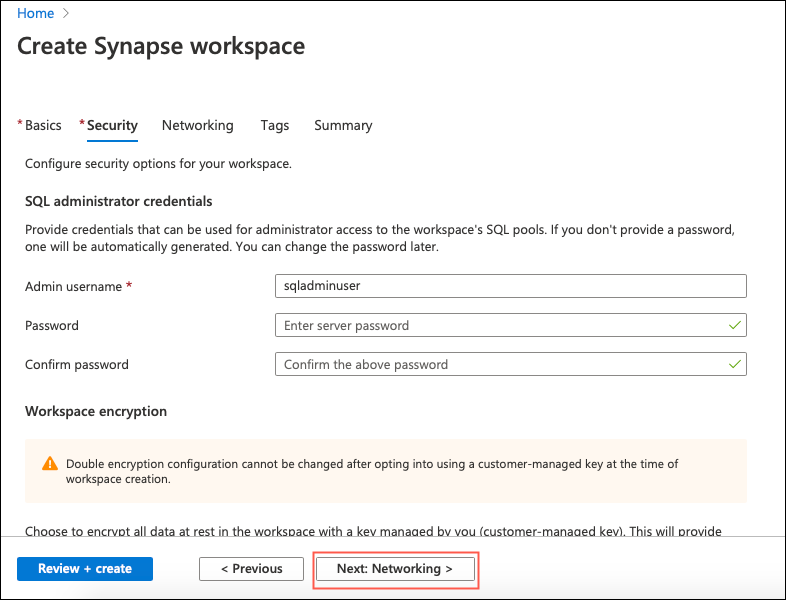
Click Next: Security >. In the “Security” tab, enter the SQL administrator credentials. If no password is provided, the password will be automatically generated. You can change the password later.
The rest of the tabs are optional. Click Review + create. The system will validate the inputs and if everything is good, you will see the “Validation succeeded” message in the “Summary” tab. Click Create to create the workspace. The deployment process will take a while to complete.
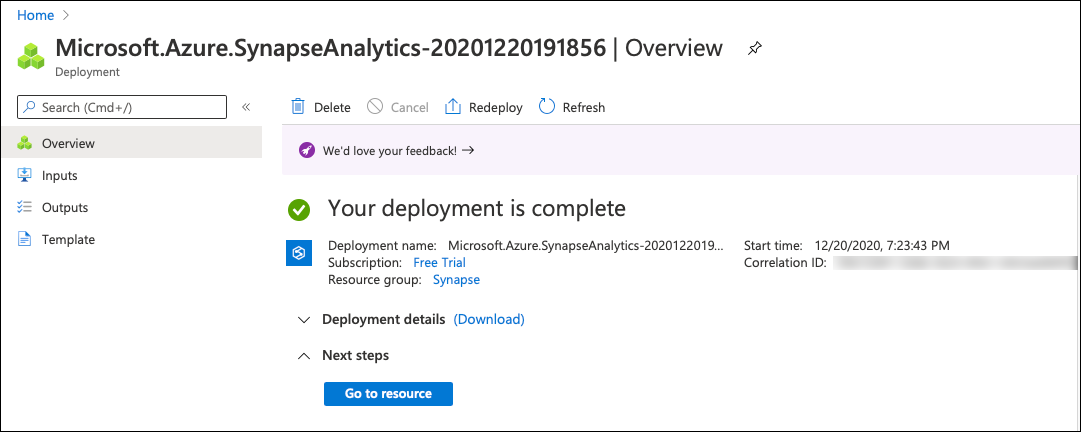
Step 2: Azure Synapse Workspace – Overview
Once the Azure Synapse Workspace has been created, click “Go to Resource” in the Overview tab. There are options to create a dedicated SQL pool, Apache Spark Pool as well as launch your Synapse Studio. You can also reset your SQL admin password from this Overview screen. Let us take a look at the steps to create each one of this.
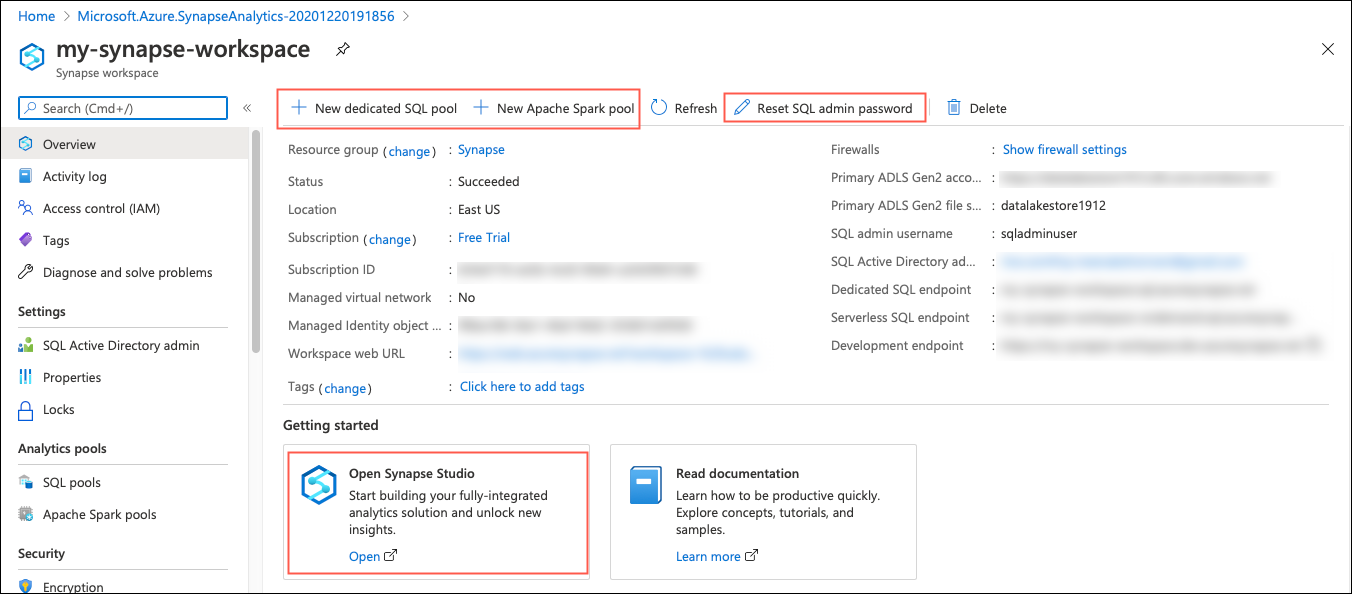
Step 2.1 – Create Dedicated SQL Pool
The SQL pool offers compute and storage capabilities. Within the SQL pool, data can be loaded, modeled as well as processed and distributed to get detailed insights of the data.
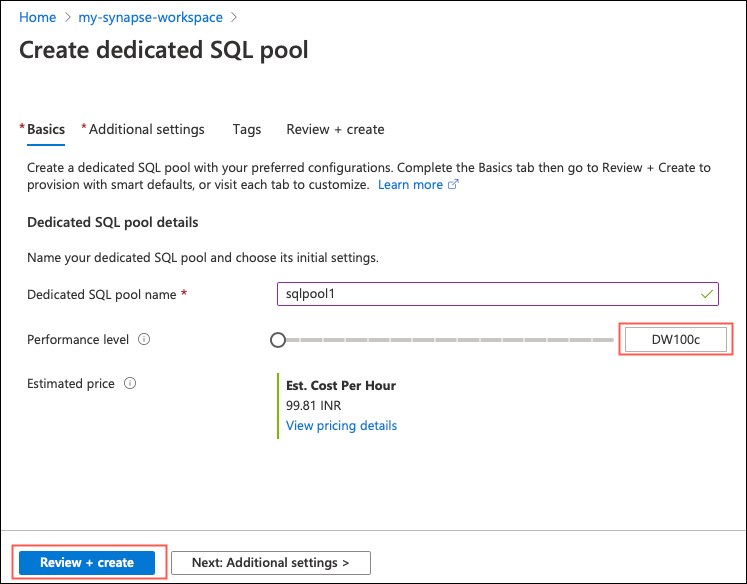
Click New dedicated SQL pool to create the SQL pool. Enter the SQL pool name as, say, sqlpool1 and set the appropriate performance level. Performance level is measured in the number of Data Warehouse Units (DWU). The DWU will decide the number of compute nodes that are required to perform the data analytics.
Note that some performance levels may not be available in your selected region. Drag the slider to select the optimum performance level. As the compute power increases with the number of compute nodes, there will be a significant increase in the cost.
In our case, we will set the performance level as DW100c. You will also see the estimated price (cost per hour) for the selected performance level. The other settings are completely optional. Click Review + Create to create the dedicated SQL pool. The system will validate the inputs and if everything is good, you will see the “Validation succeeded” message in the “Summary” tab. Click Create to create the dedicated SQL pool. The deployment process will take a while to complete.
Step 2.2 – Create Apache Spark Pool
The Apache Spark Pool offers open-source big data compute capabilities. Similar to the SQL pool, data can be loaded, modeled as well as processed and distributed to get detailed insights.
Click New Apache Spark pool to create the Apache Spark pool. Enter the name as, say, apsppool1 and select the number of nodes (drag the slider). Select the node size from the drop down. As the number of nodes increases, there will be a significant increase in the cost. You will also see the estimated price (cost per hour) for the selected number of nodes. The other settings are completely optional. Click Review + Create to create the dedicated SQL pool. The system will validate the inputs and if everything is good, you will see the “Validation succeeded” message in the “Summary” tab. Click Create to create the Apache Spark pool. The deployment process will take a while to complete.

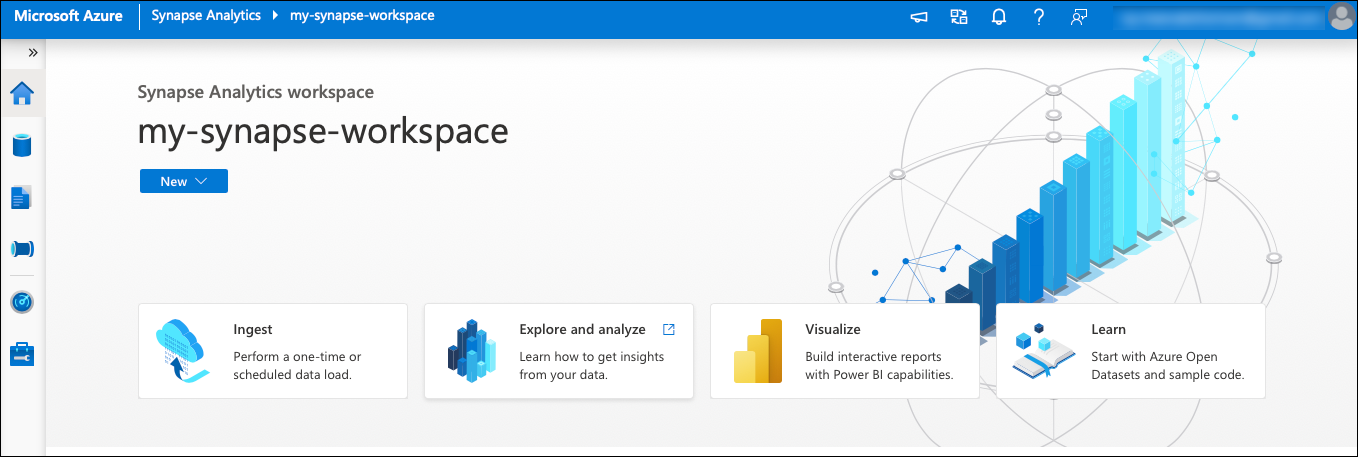
Step 3 – Launch the Synapse Studio
From the Workspace screen, open the Synapse Studio. Select the workspace (from the drop down) and click Continue. You will see four tabs – Ingest, Explore and analyze, Visualize and Learn. On the left menu, you will see the Data, Develop, Integrate, Monitor and Manage options. Here’s a quick understanding of what each section does –
Ingest – Provides an option to perform a one-time or scheduled data load from 90+ data sources using the Copy Data tool.
Visualize – You can connect the Synapse Workspace to a Power BI workspace to create reports and datasets from the data in your workspace.
Learn – For ease of use, there are predefined datasets and sample code that are readily available in the knowledge center to help you get started with the Synapse Studio
Under the Synapse Workspace name, you will find a drop down (New) with the following options – SQL Script, Notebook, Data flow, Apache Spark job definition, Pipeline and Import. These are the different ways in which you can load the data into the SQL pool or Apache Spark Pool of the Synapse workspace.
SQL Script – You can bulk load the data into a new table or an existing table within a SQL pool in the Synapse workspace.
Notebook – You can select to write a Spark code into an existing Apache Spark pool in the Synapse workspace
Data Flow – You can develop data transformation logic without writing a single line of code. Data flows provide an entirely visual experience with no coding required.
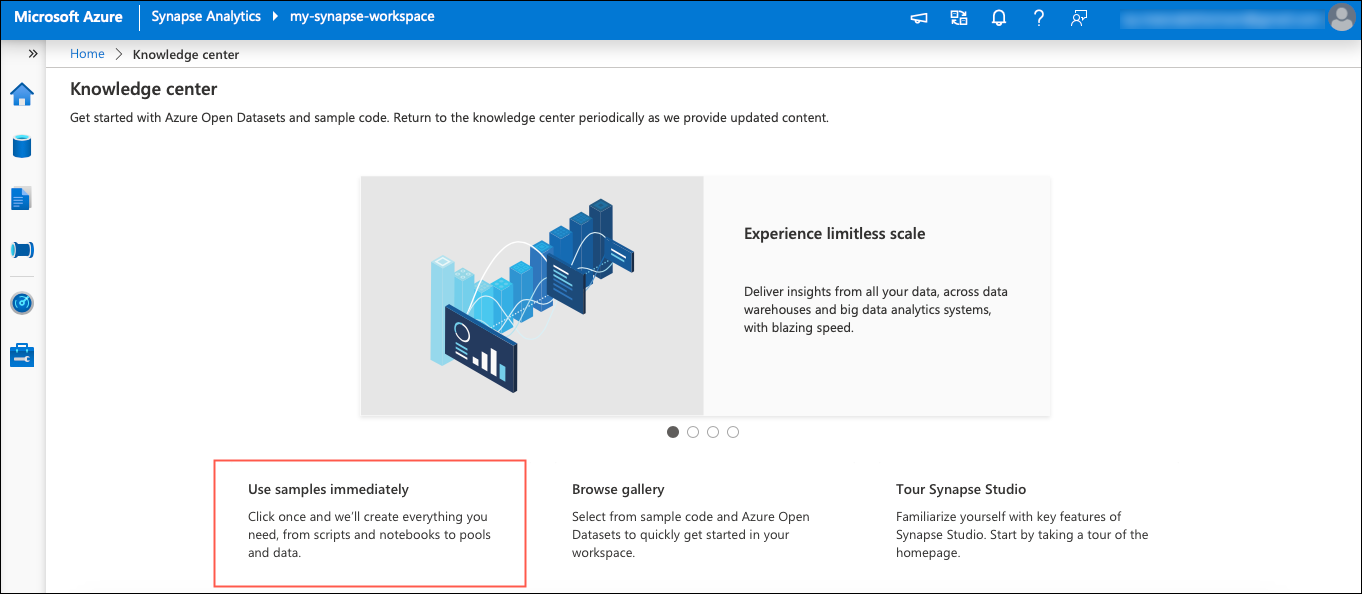
Step 3.1 – Open the Knowledge Center
We will explore and use the scripts, notebooks, datasets and pools that are already provisioned and ready for use in the Knowledge Center. Open the Knowledge Center by clicking the Learn tab. Click Use samples immediately to view the readily available samples.
There are three readily available scripts – Explore sample data with Spark, Query Data with SQL and Create an external table with SQL. Let’s take a look at one of the sample script –
Query Data with SQL
This sample consists of sample scripts and creates a SQL pool (if you do not have one already). Click Use sample.
The Query Data with SQL will query and analyze the “NYC Yellow Taxi dataset” with a serverless SQL pool. In a single click, you can visualize the result using this script. For example, we will select the first query that will select the top 100 results from the NYC taxi data.
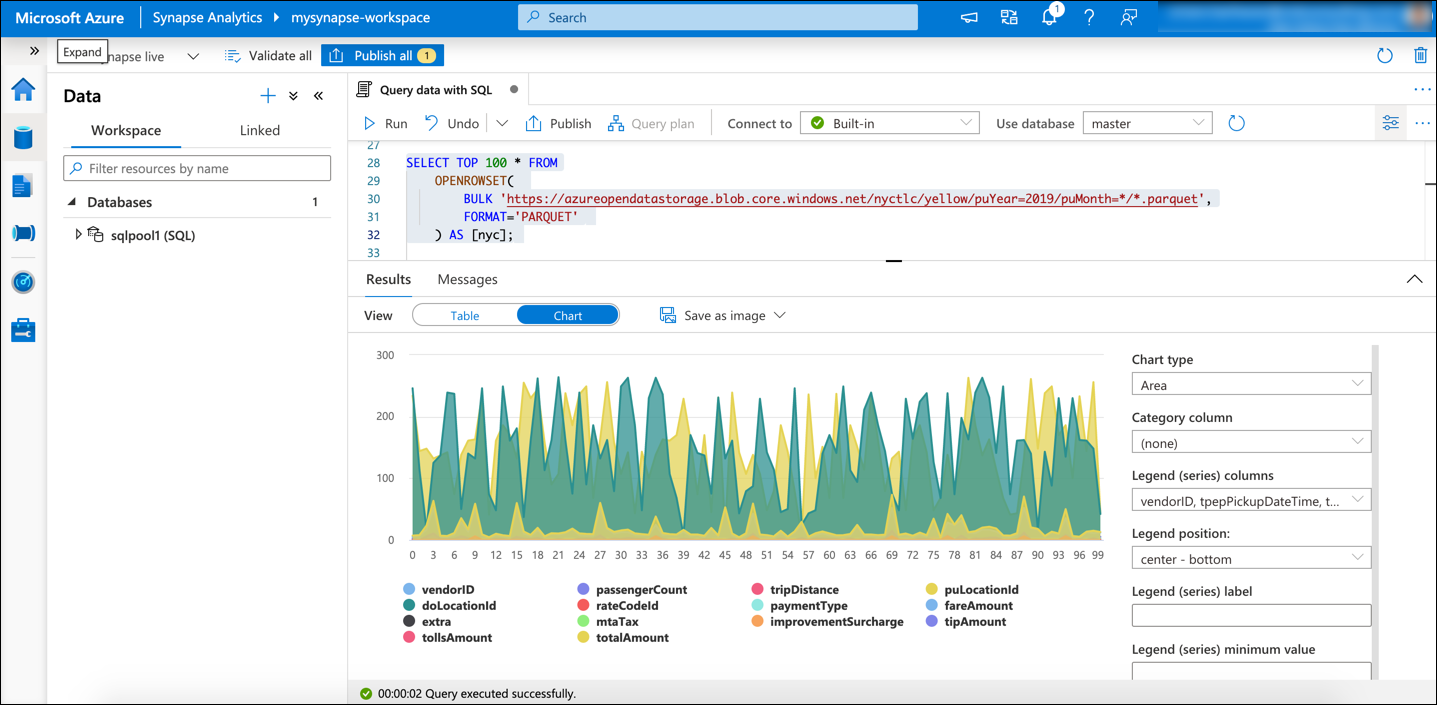
You can download the result and save it as an image (JPEG, PNG, SVG formats).
Additionally, you can also browse the gallery (Browse Gallery) to get started with different datasets. Few other interesting datasets are the “Bing COVID-19 data” sample and “COVID Tracking Project”. Select the project and click Continue.
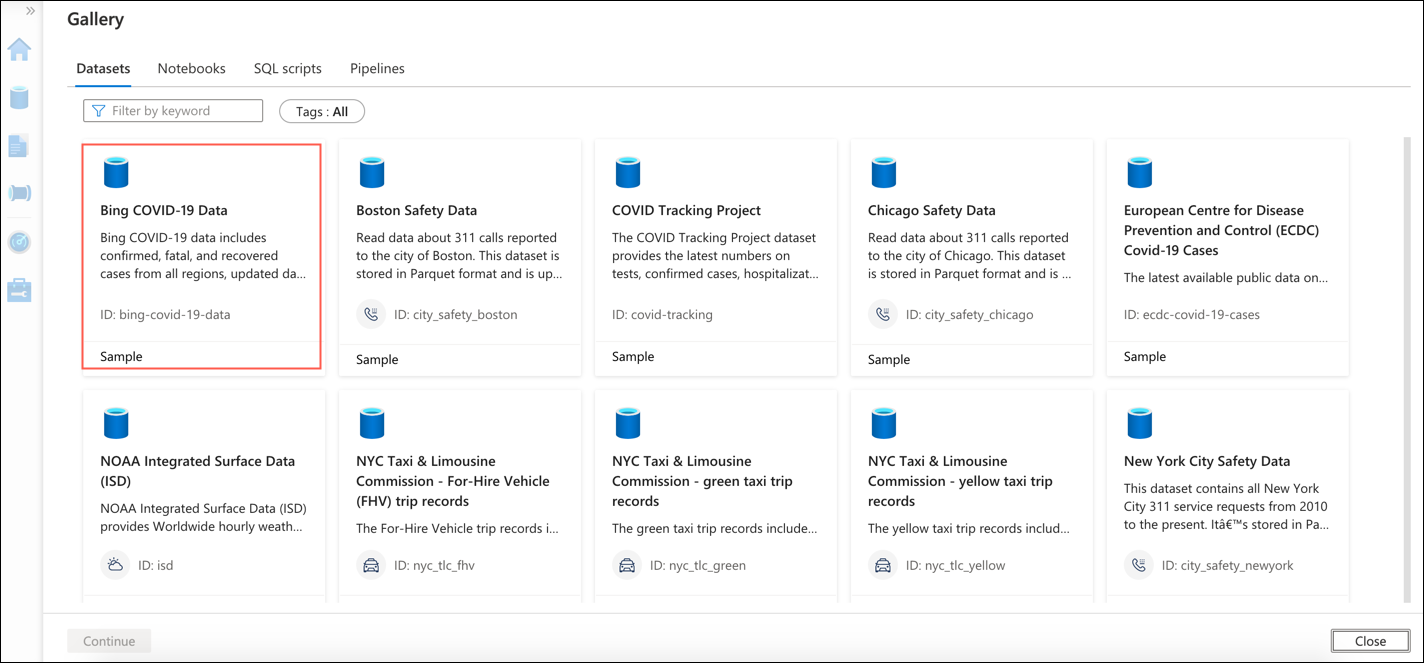
In the project description page, click Add dataset. The dataset will be added to the Synapse Studio. Using the dataset, you can create a New SQL Script (SQL Pool) or Notebook (Apache Spark Pool). For this example, we will select Sample Datasets > bing-covid-19-data > New Notebook > Load to DataFrame. Select the Apache Spark pool from the drop down. Click Run all. The execution will take some time and when successful, you will see the Job Execution as Succeeded and Spark 2 executors 16 cores.

Once the operation is complete, the pool will automatically shut down when the idle time is reached. You can specify the idle time under the Auto-pause Settings in the Apache Spark Pool within the workspace. You can also end the session from the status bar at the bottom of the notebook.
Benefits of Azure Synapse Analytics Workspace
Azure Synapse Analytics is a handy offering from Microsoft for organizations focusing on building modern data warehouses. This workspace allows the organizations to build scalable data warehouses with the capability to process huge amounts of data.
Data can be stored in various formats like structured (CSV, parquet), semi-structured (XML, JSON), unstructured such as audio/video, text files and so on. Each data format will require different processing tools (such as Spark, Python, Power BI etc.,). Synapse analytics offers rich processing and visualization tools to process the large amount of data stored in the warehouse.
Azure Synapse Analytics workspace eliminates the need for IT teams to work in silos and offers the perfect environment to work as a team. This helps them to have a clear visibility of each person’s data and processes.
Wrapping Up
With Azure Synapse Analytics Workspace, enterprises can easily connect different data sources and gather rich data insights from the data. The workspace also supports big data analytics capabilities. VNB Consulting is a Microsoft Data Analytics Gold Partner and offers consulting services for organizations to implement Azure based solutions. VNB Consulting can work with organizations to implement Azure Synapse Workspace Analytics for your business needs. Check out the recent case study on how VNB Consulting helped a healthcare firm to consolidate its intake, clinical and financial data and achieve better business insights using Azure Synapse Analytics workspace.


